监控环境基于docker和docker-compose搭建。
安装采集器
用于收集服务器的性能指标。
Linux服务器
services:
reporter_node: # 服务器指标采集,用于监控远程主机
image: prom/node-exporter:v1.7.0
restart: always
container_name: reporter_node
user: root
healthcheck:
test: ["CMD", "nc", "-zv", "localhost", "9100"]
interval: 6s
timeout: 5s
retries: 10
ports:
- 9100:9100关系数据库PostgreSQL
⚠️ 提示
启动脚本中的鉴权信息必须是实际监控环境的保持一致。
services:
reporter_pgsql: #【应用软件】
# Pgsql数据库监控 https://github.com/prometheus-community/postgres_exporter
image: prometheuscommunity/postgres-exporter:v0.15.0
restart: always
container_name: reporter_pgsql
# user: root
healthcheck:
test: ["CMD", "nc", "-zv", "localhost", "9187"]
interval: 6s
timeout: 5s
retries: 10
ports:
- 9187:9187
environment:
- DATA_SOURCE_URI=部署内网ip:5432/thingskit?sslmode=disable
- DATA_SOURCE_USER=thingskit
- DATA_SOURCE_PASS=thingskit安装Prometheus
是一款基于时序数据库的开源监控告警系统。
services:
prometheus:
image: prom/prometheus:v2.42.0
volumes:
- ./conf/prometheus/:/etc/prometheus/:ro
- /var/_datas/prometheus:/prometheus/data
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.config.file=/etc/prometheus/web_auth.yml' #身份认证配置文件
- '--storage.tsdb.retention.time=120d'
ports:
- 9090:9090
restart: always
container_name: prometheus
user: root
# my global config
global:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # By default, scrape targets every 15 seconds.
# scrape_timeout is set to the global default (10s).
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'thingskit'
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
basic_auth:
username: thingskit
password: thingskit
scrape_interval: 5s
static_configs:
- targets: ['部署内网ip:9090']
- job_name: 'cluster_nodes' #服务节点指标采集
static_configs:
- targets: ['部署内网ip:9100']
- job_name: 'cluster_pgsql'
# metrics_path: /actuator/prometheus
static_configs:
- targets: ['部署内网ip:9187']
- job_name: 'tb-core'
metrics_path: /actuator/prometheus
static_configs:
- targets: [ '部署内网ip:8080' ]
安装grafana
grafana作为数据可视化与分析工具。
version: '3'
services:
grafana:
image: grafana/grafana
user: "472"
depends_on:
- prometheus
ports:
- 13000:3000
volumes:
# - ./conf/grafana/:/etc/grafana/provisioning/:ro
- ./data/grafana/:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=thingskit
- GF_USERS_ALLOW_SIGN_UP=false
restart: always
container_name: grafana登录方式
💡 提示
默认账号:admin
默认密码:thingskit
默认登录端口:13000

配置数据源

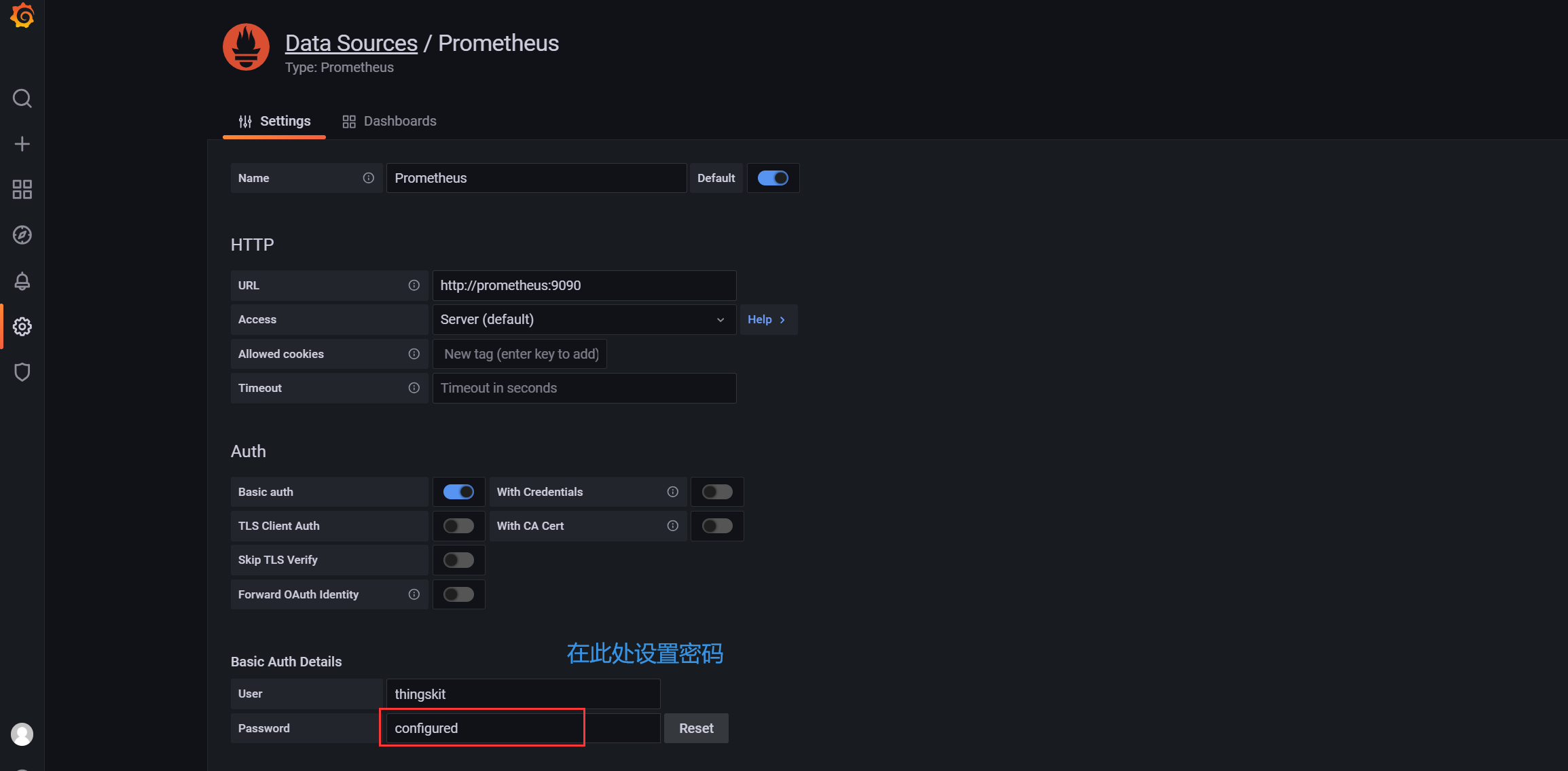
默认密码为thingskit
导入看板
看板市场
Linux服务器
模板ID:1860
关系数据库PostgreSQL
模板ID:9628
平台服务组件
模板ID:4701
功能介绍
💡 提示
导入看板后,可以根据当前需求查询对应看板。
看板进入方式:
过滤显示方式:
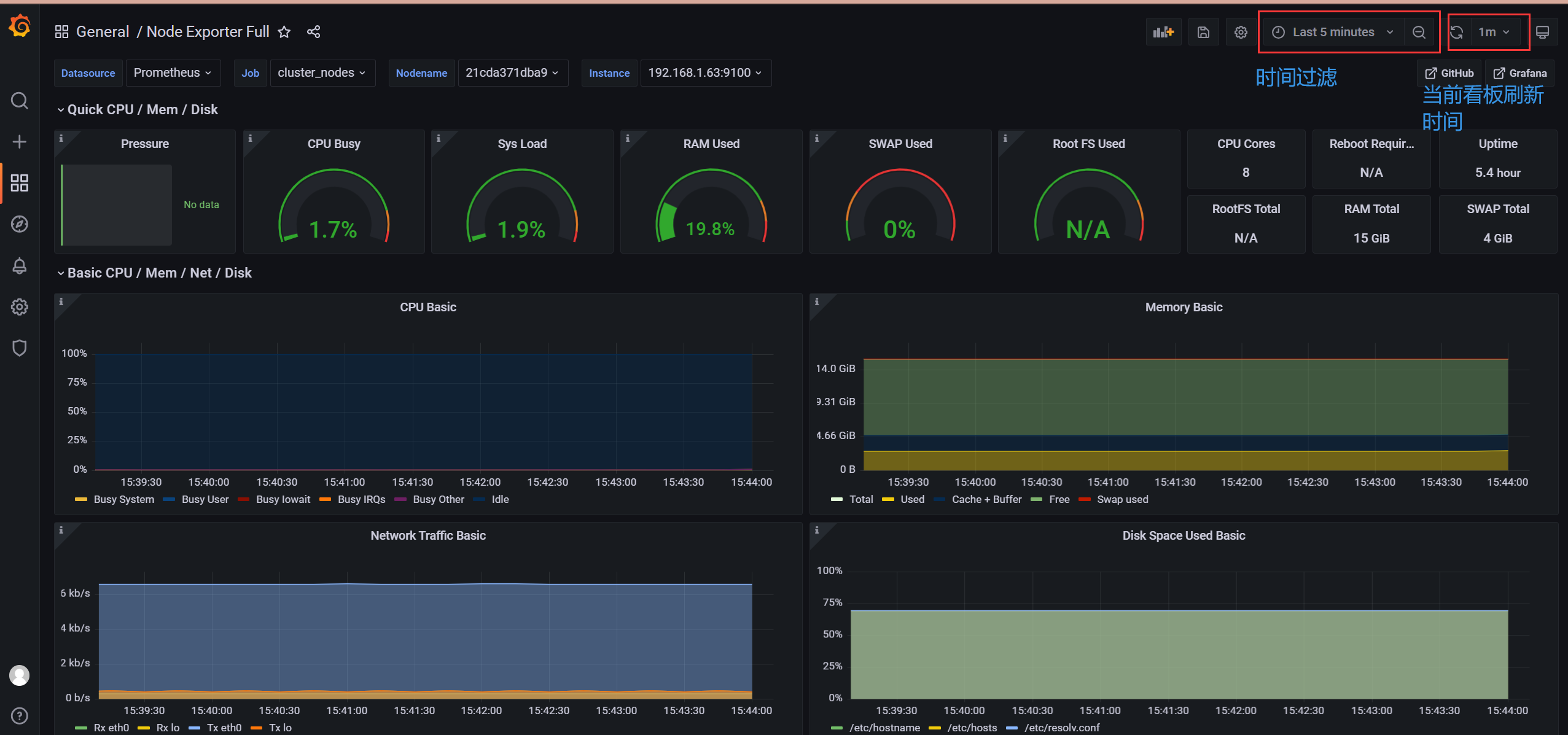
附录
mqtt模拟测试工具启动方式
cd /mqtt_simulator/ #切换至启动目录
chmod +x java-start.sh #添加脚本执行权限
./java-start.sh #启动脚本测试结论
测试场景
- 5000台设备;
- 单体部署;
- 通过MQTT每秒5000条消息,每条MQTT消息包含3个数据点,每秒产生15000个数据点;
- PostgreSQL数据库;
- TimescaleDB时序插件。
测试方法
在单个服务器上部署ThingsKit单体实例(服务器配置见下面表格),以及所有相关的第三方组件。通过模拟器,模拟5000台设备连接并上报数据,通过模拟器不断用MQTT发布时间序列数据。
本次测试,模拟平台管理智能电表设备,以JSON数据格式发送消息,其中包含三个数据点:脉冲计数器、泄漏标识和电池电量。每个设备都使用单独的MQTT连接到服务器。ThingsKit物联网平台将所有时间序列数据存储在数据库中。
测试服务器及安装信息
|
实例类型 |
安装程序 |
数据库 |
测试设备数 |
测试点位数 |
|
8 核CPU、16GB内存 |
ThingsKit基础版 |
PostgreSQL+ TimescaleDB |
5000台 |
15000点/s |
总结
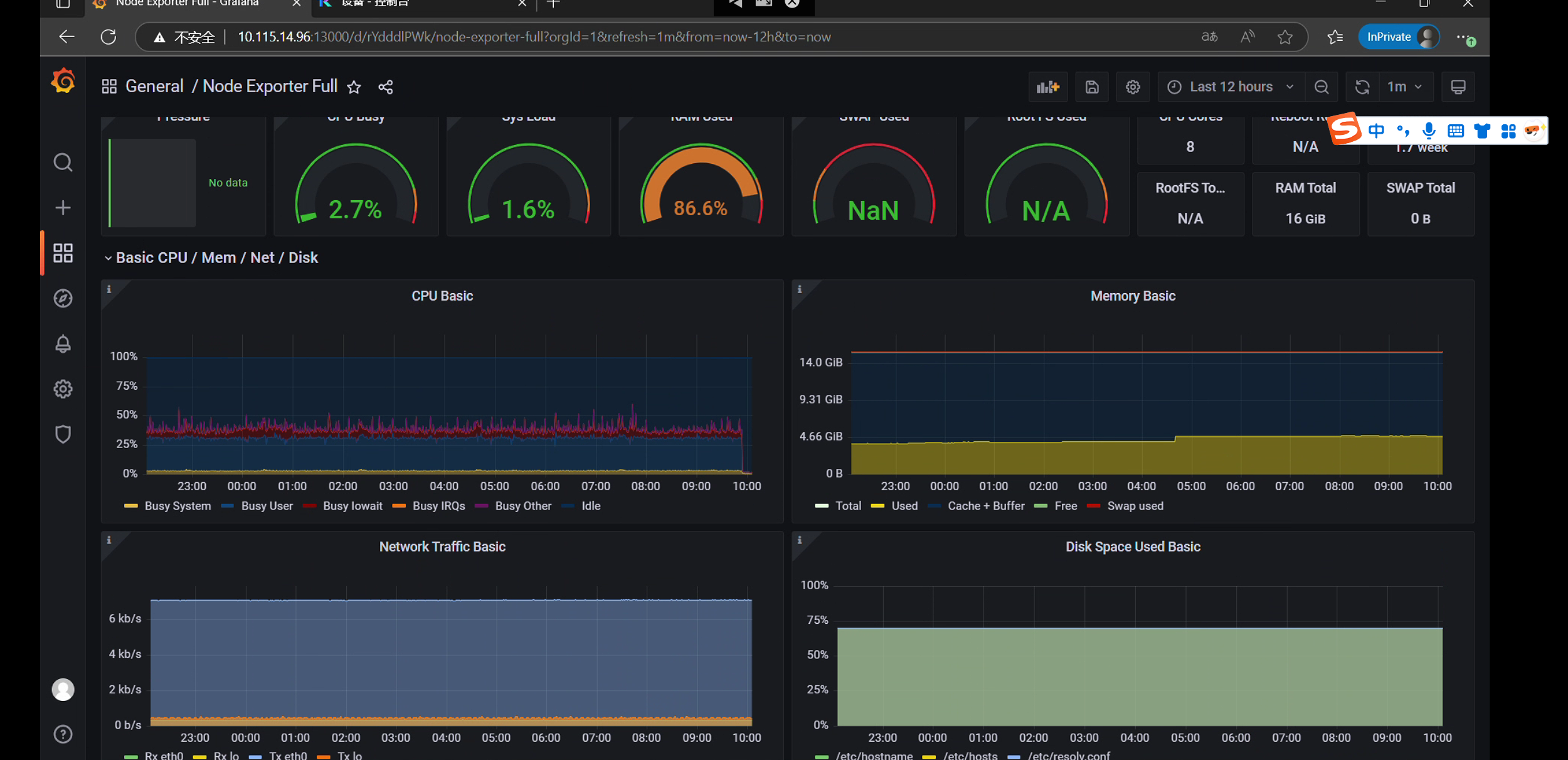
据上述测试过程监控分析得出测试结论:在该测试环境下运行,平台支持5K设备同时在线和1.5W每秒的数据并发,CPU消耗平稳50%左右;内存消耗在系统资源消耗5GB左右;平台运行状态一切正常。
💡 提示:
本次测试考虑到生产环境的异构性和复杂性,测试指标并未设计为极限测试指标,理论上5K设备和1.5W的数据并发还可以提高。